Monday, Sept. 9
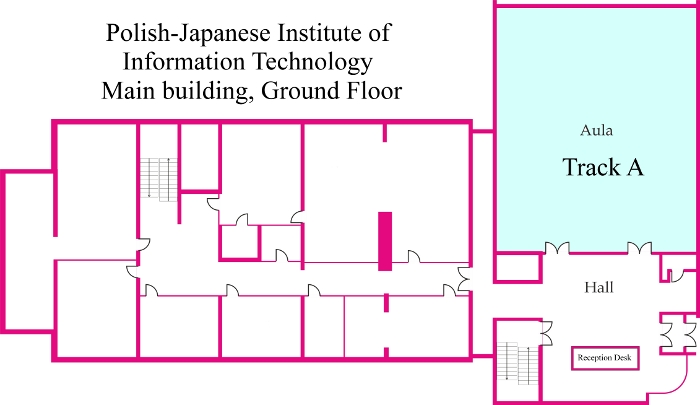
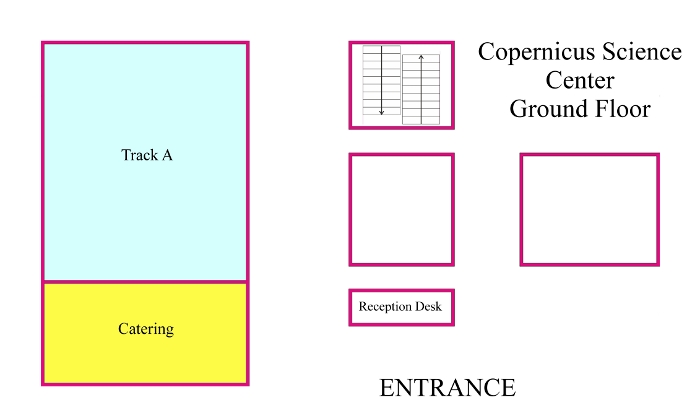
Copernicus Science Center
The organizers provide buses to Copernicus Science Center from hotels: Campanile, Golden Tulip and Premiere Classe - departure at 8:15
|
|
From 9:00
|
Registration
|
|
9:10
|
Opening
|
|
9:30 – 10:50
|
Invited talks

Chairperson: Fran Berman
- An Overview of High Performance Computing and Challenges for the Future - Jack Dongarra, University of Tennessee and Oak Ridge National Laboratory
- From Principles to Capabilities – The Birth and Evolution of High Throughput Computing - Miron Livny, University of Wisconsin
|
|
10:50 – 11:20
|
Coffee break
|
|
11:20 – 13:00
|
Contributed papers (6 x 4 slots)
-
Track A: WS on Power and Energy Aspects of Computation
Chairperson: Piotr Luszczek
- Invited talk:
Monitoring Performance and Power for Application Characterization with Cache-aware Roofline Model - Leonel Sousa
- Energy and deadline constrained robust stochastic static resource allocation - M. Oxley, S. Pasricha, H. Siegel, A. Maciejewski
- Performance and energy analysis of the iterative solution of sparse linear systems on multicore and manycore architectures - J. I. Aliaga, M. Castillo, J. C. Fernandez, G. Leon, J. Perez, E. S. Quintana-Orti
-
Track B: Main Track: Numerical Algorithms and Parallel Scientific Computing
Chairperson: Marian Vajtersic
- Performance of dense eigensolvers on BlueGene/Q - I. Gutheil, J. F. Muenchhalfen, J. Grotendorst
- Experiences with a Lanczos eigensolver in high-precision arithmetic - A. Alperovich, A. Druinsky, S. Toledo
- Adaptive load balancing for massively parallel multi-level Monte Carlo solvers - J. Sukys
- A simple implementation of parareal-in-time on a parallel bucket-brigade interface - T. Takami, D. Fukudome
-
Track C: MS on Applications of Parallel Computation in Industry and Engineering
Chairpersons: Raimondas Ciegis, and Julius Zilinskas
- A parallel solver for the time-periodic Navier-Stokes equations - P. Arbenz, D. Hupp, D. Obrist
- Parallel numerical algorithms for simulation of rectangular waveguides using GPU - R. Ciegis, A. Bugajev, Z. Kancleris, G. Slekas
- OpenACC parallelisation for diffusion problems, applied to temperature distribution on a honeycomb around the bee brood: a worked example using BiCGSTAB - H. Eberl, R. Sudarsan
- Application of CUDA for acceleration of calculations in boundary value problems solving using PIES - A. Kuzelewski, E. Zieniuk, A. Boltuc
-
Track D: Main Track: Environments and Tools for Distributed/Cloud/Grid Computing
Chairperson: Marek Tudruj
- Development of Domain-Specific Solutions within the Polish Infrastructure for Advanced Scientific Research - J. Kitowski, P. Bala, M. Borcz, A. Czyzewski, L. Dutka, R. Kluszczynski, J. Kotus, P. Kustra, N. Meyer, A. Milenin, Z. Mosurska, R. Pająk, L. Rauch, M. Sterzel, D. Stoklosa, T. Szepieniec
- Cost optimization of execution of multi-level deadline-constrained scientific workflows on clouds - M. Malawski, K. Figiela, M. Bubak, E. Deelman, J. Nabrzyski
- Parallel computations in the volunteer based Comcute system - P. Czarnul, J. Kuchta, M. Matuszek
- Distributed program execution control based on application global states monitoring in PEGASUS DA framework - M. Tudruj, J. Borkowski, D. Kopanski, L. Masko, E. Laskowski, A. Smyk
-
Track E: WS on Complex Collective Systems
Chairpersons: Pawel Topa, and Jaroslaw Was
- Bridging the gap: from Cellular Automata to differential equation models for pedestrian dynamics - F. Dietrich, G. Koester, M. Seitz, I. von Sivers
- Cellular model of pedestrian dynamics with adaptive time span - M. Bukáček, P. Hrabak, M. Krbalek
- The use of GPGPU in continuous and discrete models of crowd dynamics - H. Mróz, J. Wąs, P. Topa
- Modeling behavioral traits of employees in a workplace with Cellular Automata - P. Saravakos, G. Ch. Sirakoulis
-
Track F: WS on Models, Algorithms and Methodologies for Hierarchical Parallelism in new HPC Systems
Chairpersons: Giuliano Laccetti, Marco Lapegna, and Raffaele Montella
- Transparent application acceleration by intelligent scheduling of shared library calls on heterogeneous systems - J. Colaço, A. Matoga, A. Ilić, N. Roma, P. Tomás, R. Chaves
- Improving parallel I/O performance using multithreaded two-phase I/O with processor affinity management - Y. Tsujita, K. Yoshinaga, A. Hori, M. Sato, M. Namiki, Y. Ishikawa
- Storage systems for organizationally distributed environments - PLGrid PLUS case study - R. Slota, L. Dutka, B. Kryza, D. Nikolow, D. Król, M. Wrzeszcz, J. Kitowski
- The high performance Internet of Things: using GVirtuS for gluing cloud computing and ubiquitous connected devices - R. Montella, G. Laccetti
|
|
13:00 – 14:00
|
Lunch
|
|
14:00 – 15:20
|
Invited talks (in parallel)
Track A:
Chairperson: Miron Livny
- Building a Global Research Data Community - Fran Berman, Rensselaer Polytechnic Institute
- Big Data in the Cloud: Research and Education - Geoffrey Fox, Indiana University, USA
Track B:
Chairperson: Leonel Sousa
- More Science per Joule: Bottleneck Computing - Georg Hager, University of Erlangen-Nuremberg
- Debugging and Optimizing Parallel Applications with TotalView and ThreadSpotter - Dean Stewart, Rogue Wave Software
|
|
15:20 – 15:50
|
Coffee break
|
|
15:50 – 18:00
|
Contributed papers (6 x 5 slots)
-
Track A: MS on GPU Computing
Chairpersons: Jose Herrero, Enrique Quintana-Orti, and Robert Strzodka
- Evaluation of autoparallelization toolkits for commodity graphics hardware - D. Williams, V. Codreanu, P. Yang, B. Liu, F. Dong, B. Yasar, B. Mahdian, A. Chiarini, X. Zhao, J. Roerdink
- Real-time multiview human body tracking using GPU-accelerated PSO - B. Rymut, B. Kwolek
- Implementation of a heterogeneous image reconstruction system for clinical Magnetic Resonance - G. Kowalik, J. Steeden, D. Atkinson, A. Taylor, V. Muthurangu
- X-ray laser imaging of biomolecules using multiple GPUs - S. Engblom, J. Liu
- Out-of-core solution of eigenproblems for macromolecular simulations on GPUs - J. I. Aliaga, D. Davidovic, E. S. Quintana-Ortí
-
Track B: WS on Numerical Algorithms on Hybrid Architectures
Chairperson: Beata Bylina
- Performance evaluation of sparse matrix multiplication kernels on Intel Xeon Phi - E. Saule, K. Kaya, U. Catalyurek
- Portable HPC programming on Intel Many-Integrated-Core hardware with MAGMA port to Xeon Phi - J. Dongarra, M. Gates, A. Haidar, Y. Jia, K. Kabir, P. Luszczek, S. Tomov
- Accelerating a massively parallel numerical simulation in electromagnetism using a cluster of GPUs - C. Augonnet, D. Goudin, A. Pujols, M. Sesques
- Multidimensional Monte Carlo integration on clusters with hybrid GPU-accelerated nodes - D. Szalkowski, P. Stpiczynski
- Efficient execution of erasure codes on AMD APU architecture - M. Woźniak, L. Kuczynski, R. Wyrzykowski
-
Track C: Main Track: Applications of Parallel Computing
Chairperson: Ondrej Jakl
- New scalable SIMD-based ray caster implementation for virtual machining - T. Welsch, A. Leutgeb, M. Hava
- Parallelization of permuting schema-less XML compressors - T. Corbin, T. Muldner, J. K. Miziołek
- Parallel processing model for syntactic pattern recognition-based electrical load forecast - M. Flasinski, J. Jurek, T. Peszek
- Parallel event-driven simulation based on application global state monitoring - L. Masko, M. Tudruj
-
Track D: Workshop on Applied High Performance Numerical Algorithms in PDEs
Chairpersons: Piotr Krzyzanowski, and Leszek Marcinkowski
- A Domain decomposition method for discretization of multiscale elliptic problems by discontinuous Galerkin method - M. Dryja
- Parallel preconditioner for finite volume element discretization of elliptic problem - L. Marcinkowski, T. Rahman
- Abstract Schwarz method for nonsymmetric local discontinuous Galerkin discretization of elliptic problem - F. Klawe
- Fast numerical method for 2D initial-boundary value problems for the Boltzmann equation - A. Heintz, P. Kowalczyk
- Simulating phase transition dynamics on nontrivial domains - M. Gokieli, Ł. Bolikowski
-
Track E: Main Track: Applied Mathematics, Evolutionary Computing and Metaheuristics
Chairperson: Franciszek Seredynski
- It's not a bug, it's a feature. Wait-free asynchronous cellular genetic algorithm - F. Pinel, B. Dorronsoro, P. Bouvry, S. Khan
- Evolutionary algorithms for abstract planning - J. Skaruz, A. Niewiadomski, W. Penczek
- Solution of the inverse continuous casting problem with the aid of modified harmony search algorithm - E. Hetmaniok, D. Slota, A. Zielonka
- Influence of a topology of a spring network on its ability to learn mechanical behaviour - M. Czoków, J. Miękisz
-
Track F: MS on High Performance Computing Interval Methods
Chairperson: Bartlomiej Kubica, and Pawel Sewastjanow
- A shaving method for interval linear systems of equations - M. Hladík , J. Horáček
- Inner estimation of linear parametric AE-solution sets - E. Popova
- Finding enclosures for linear systems using interval matrix multiplication in CUDA - A. Dallmann, P. Beck
- GPU accelerated metaheuristics for solving large scale parametric interval algebraic systems - I. Skalna, J. Duda
- Parallel approach to Monte Carlo simulation for option price sensitivities using the adjoint and interval analysis - G. Kozikowski, B. Kubica
|
|
18:15
|
Travelling by buses to Wilanow Palace (directly from the Copernicus Science Center), excursion, and barbecue in "Nowa Kuźnia"
|
Tuesday, Sept. 10
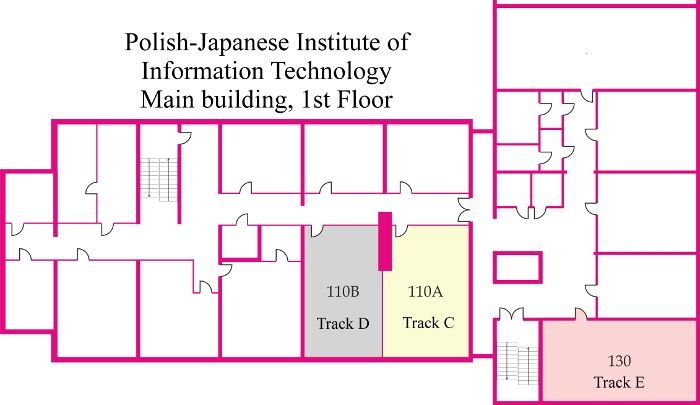
Polish-Japanese Institute
|
|
8:30 – 9:50
|
Invited talks
Chairperson: Jack Dongarra
- Legacy at Exascale: A Contradiction? A Software Approach to Achieving It - Robert Wisniewski, Intel
- The Changing Face of Advanced Computing and the Convergence of Modeling, Simulation, Analytics and Big Data - James Sexton, IBM T.J.Watson Research Center
|
|
9:50 – 10:20
|
Coffee break
|
|
10:20 – 12:25
|
Contributed papers (6 x 5 slots)
-
Track A: Main Track: Numerical Algorithms and Parallel Scientific Computing
Chairperson: Jacek Kitowski
- Methods for high-throughput computation of elementary functions - M. Dukhan, R. Vuduc
- Engineering nonlinear pseudorandom number generators - S. Neves, F. Araujo
- Extending the generalized Fermat prime number search beyond one million digits using GPUs - I. Bethune, M. Goetz
- Iterative solution of singular systems with applications - R. Blaheta, O. Jakl, J. Starý, E. Turan
- Statistical estimates for the conditioning of linear least squares problems - M. Baboulin, S. Gratton, R. Lacroix, A. Laub
-
Track B: WS on Numerical Algorithms on Hybrid Architectures
Chairperson: Przemyslaw Stpiczynski
- AVX acceleration of DD arithmetic between a sparse matrix and vector - T. Hishinuma, A. Fujii, T. Tanaka, H. Hasegawa
- Using quadruple precision arithmetic to accelerate Krylov subspace methods on GPUs - D. Mukunoki, D. Takahashi
- Effectiveness of sparse data structure for double-double and quad-double arithmetics - T. Saito, S. Kikkawa, E. Ishiwata, H. Hasegawa
- Efficient heuristic adaptive quadrature on GPUs: design and evaluation - D. Thuerck, S. Widmer, A. Kuijper, M. Goesele
- Square block code for positive definite symmetric Cholesky band routines - F. G. Gustavson, J. R. Herrero, E. Morancho
-
Track C: WS on Language-Based Parallel Programming Models
Chairperson: Ami Marowka
- Towards standardization of measuring the usability of parallel languages - A. Marowka
- Experiences with implementing task pools in Chapel and X10 - C. Fohry, J. Breitbart
- Parampl: A simple approach for parallel and distributed execution of AMPL programs - A. Olszak, A. Karbowski
- Optimization of an OpenCL-based multi-swarm PSO algorithm on an APU - W. Franz, P. Thulasiraman, R. Thulasiram
- Algorithms for in-place matrix transposition - F. G. Gustavson, D. Walker
-
Track D: Workshop on Applied High Performance Numerical Algorithms in PDEs
Chairpersons: Piotr Krzyzanowski, and L. Marcinkowski
- Variable block multilevel iterative solution of general sparse linear systems - B. Carpentieri, J. Liao, M. Sosonkina
- An automatic way of finding optimal elimination trees for sequential and parallel multi-frontal direct solver for adaptive finite element method - H. Aboueisha, P. Gurgul, A. Paszynska, M. Paszynski, M. Moshkov, K. Kuźnik
- Parallel efficiency of an adaptive, dynamically balanced flow solver - S. Gepner, J. Majewski, J. Rokicki
- Modification of the Newton's method for the simulations of gallium nitride semiconductor devices - K. Sakowski, L. Marcinkowski, S. Krukowski
- A project of numerical realization of the one-dimensional model of burning methanol - K. Moszynski
-
Track E: WS on Complex Collective Systems
Chairpersons: Pawel Topa, and Jaroslaw Was
- Probabilistic pharmaceutical modelling: a comparison between synchronous and asynchronous Cellular Automata - M. Bezbradica, H. J. Ruskin, M. Crane
- Coupling lattice Boltzmann gas and level set method for simulating free surface flow in GPU/CUDA environment - T. Kryza, W. Dzwinel
- Creation of agent's vision of social network through episodic memory - M. Wrzeszcz, J. Kitowski
- The influence of multi-agent cooperation on the efficiency of taxi dispatching - M. Maciejewski, K. Nagel
- Basic endogenous-money economy: an agent-based approach - I. Blecic, A. Cecchini, G. A. Trunfio
-
Track F: MS on High Performance Computing Interval Methods
Chairperson: Bartlomiej Kubica, and Pawel Sewastjanow
- Subsquares approach - simple scheme for solving overdetermined interval linear systems - J. Horáček, M. Hladík
- Using quadratic approximations in an interval method of solving underdetermined and well-determined nonlinear systems - B. Kubica
- Interval finite difference method for solving the problem of bioheat transfer between blood vessel and tissue - M. A. Jankowska
- Chosen interval methods for solving an interval linear system of equations - B. Szyszka
- Numerical reproducibility in HPC: the interval point of view - N. Revol, P. Theveny
|
|
12:25 – 14:00
|
Lunch and poster session
Chairperson: Roman Wyrzykowski
- Improving perfect parallelism - L. Karlsson, C. Christian K. Mikkelsen, B. Kågström
- Parallel one-sided Jacobi SVD algorithm with variable blocking factor - M. Becka, G. Oksa
- Using Intel Xeon Phi coprocessor to accelerate computations in MPDATA algorithm - L. Szustak, K. Rojek, P. Gepner
- Genetic programming in automatic discovery of relationships in computer system monitoring data - P. Koperek, W. Funika
- Genetic algorithms execution control under a global application state monitoring infrastructure - A. Smyk, M. Tudruj
- Non-perturbative methods in phenomenological simulations of ring-shape molecular nanomagnets - P. Kozłowski, G. Musiał, M. Haglauer, W. Florek, M. Antkowiak, F. Esposito, D. Gatteschi
- Non-uniform quantum spin chains: static and dynamic properties - A. Barasinski, B. Brzostowski, R. Matysiak, P. Sobczak, D. Wozniak
- Neighborhood selection and rules identification for cellular automata: a rough sets approach - B. Płaczek
- The graph of Cellular Automata applied for modelling tumour induced angiogenesis - P. Topa
- Preconditioning iterative substructuring methods using inexact local solvers - P. Krzyzanowski
- An efficient representation on GPU for transition rate matrices for Markov chains - J. Bylina, B. Bylina, M. Karwacki
- Eigen-G: GPU-based eigenvalue solver for real-symmetric dense matrices - T. Imamura, S. Yamada, M. Machida
- A study on adaptive algorithms for numerical quadrature on hybrid GPU and multicore based systems - G. Laccetti, M. Lapegna, V. Mele, D. Romano
- The definition of interval-valued intuitionistic fuzzy sets in the framework of Dempster-Shafer theory - L. Dymova, P. Sevastjanov
|
|
14:00 – 15:20
|
Invited talks (in parallel)
Track A:
Chairperson: Ewa Deelman
- Parallel DAG Scheduling: Recent Results and New Directions - Rizos Sakellariou, University of Manchester
- Exploring Emerging Technologies in the HPC Co-Design Space - Jeffrey Vetter, ORNL and Georgia Institute of Technology
Track B:
Chairperson: David Bader
- Optimization of data parallel applications for heterogeneous and hierarchical HPC platforms based on multicores and multi-GPUs - Alexey Lastovetsky, University College Dublin
- Algebra and Geometry Combined Explains How the Human Mind Does Applied Math - Fred Gustavson, IBM T.J. Watson Research Center and Umea University
|
|
15:20 – 15:40
|
Coffee break
|
|
15:40 – 18:10
|
Contributed talks (6 x 6 slots)
-
Track A: Main Track: Numerical Algorithms and Parallel Scientific Computing
Chairperson: Inge Gutheil
- Numerical treatment of a cross-diffusion model of biofilm exposure to antimicrobials - K. Rahman, H. Eberl
- Performance analysis for stencil-based 3D MPDATA algorithm on GPU architecture - K. Rojek, L. Szustak, R. Wyrzykowski
- Elliptic solver performance evaluation on modern hardware architectures - M. Ciznicki, P. Kopta, M. Kulczewski, K. Kurowski, P. Gepner
- Parallel geometric multigrid preconditioner for 3D FEM in NuscaS software package - T. Olas
- Scalable parallel generation of very large sparse benchmark matrices - D. Langr, I. Šimeček, P. Tvrdík, T. Dytrych
-
Track B: MS on GPU Computing (2 slots)
Chairpersons: Jose Herrero, Enrique Quintana-Orti, and Robert Strzodka
- GPU implementation of the Monte-Carlo simulations of the extended Ginzburg-Landau mode - P. Bialas, J. Kowal, A. Strzelecki
- Using GPUs for parallel stencil computations in relativistic hydrodynamic simulation - S. Cygert, D. Kikoła, J. Porter-Sobieraj, J. Sikorski, M. Słodkowski
Special Session on Multicore Systems (4 slots)
Chairpersons: Suleyman Tosun, and Ozcan Ozturk
- PDNOC: an efficient partially diagonal network-on-chip design - T. C. Xu, V. Leppänen, P. Liljeberg, J. Plosila, H. Tenhunen
- Adaptive fork-heuristics for software thread-level speculation - Z. Cao, C. Verbrugge
- Inexact sparse matrix vector multiplication in Krylov subspace methods: An application-oriented reduction method - A. Mansour, J. Götze
- The regular expression matching algorithm for the energy efficient reconfigurable SoC - P. Russek, K. Wiatr
-
Track C: WS on Scheduling for Parallel Computing
Chairperson: Maciej Drozdowski
- Scheduling Bag-of-Tasks Applications to Optimize Computation Time and Cost - A. Grekioti, N. V. Shakhlevich
- Scheduling Moldable Tasks with Precedence Constraints and Arbitrary Speedup Functions on Multiprocessors - S. Hunold
- OStrich: Fair Scheduling for Multiple Submissions - J. Emeras, V. Pinheiro, K. Rzadca, D. Trystram
- Fair share is not enough: measuring fairness in scheduling with cooperative game theory - P. Skowron, K. Rzadca
- Setting up clusters of computing units to process several data streams efficiently - D. Millot, C. Parrot
-
Track D: WS on Performance Evaluation of Parallel Applications on Large-Scale Systems
Chairperson: Jan Kwiatkowski
- The effect of parallelization on a tetrahedral mesh optimization method - D. Benitez, E. Rodríguez, J. M. Escobar, R. Montenegro
- Analysis of partitioning models and metrics in parallel sparse matrix-vector multiplication - K. Kaya, B. Ucar, U. Catalyurek
- Achieving memory scalability in the Gysela code to fit exascale constraints - G. Latu, J. Roman, F. Rozar
- Probabilistic analysis of barrier eliminating method applied to load-imbalanced parallel application - N. Yonezawa, K. Katou, I. Kino, K. Wada
- Multi-GPU parallel memetic algorithm for capacitated vehicle routing problem - M. Wodecki, W. Bozejko, M. Karpiński, M. Pacut
- Parallel applications performance evaluation using the concept of granularity - J. Kwiatkowski
-
Track E: WS on Parallel Computational Biology
Chairperson: Bertil Schmidt
- Resolving load balancing issues in BWA on NUMA multicore architectures - C. Herzeel, T.J. Ashby, P. Costanza, W. De Meuter
- K-mulus: strategies for BLAST in the cloud - C. Hill, C. Albach, S. Angel, M. Pop
- Faster GPU-accelerated Smith-Waterman Algorithm with Alignment Backtracking for Short DNA Sequences - Y. Liu, B. Schmidt
- Accelerating string matching on MIC architecture for motif extraction - S. Pissis, C. Goll, P. Pavlidis, A. Stamatakis
- A parallel, distributed-memory framework for comparative motif discovery - D. De Witte, M. Van Bel, P. Audenaert, P. Demeester, B. Dhoedt, K. Vandepoele, J. Fostier
- Parallel seed-based approach to protein structure similarity detection - G. Chapuis, M. Le Boudic - Jamin, R. Andonov, H. Djidjev, D. Lavenier
-
Track F: MS on HPC Applications in Physical Sciences
Chairpersons: Grzegorz Kamieniarz, and Wojciech Florek
- Simulations of the adsorption behavior of dendrimers - J. Klos, J. Sommer
- An optimized Lattice Boltzmann code for BlueGene/Q - M. Pivanti, F. Mantovani, S. F. Schifano, R. Tripiccione, L. Zenesin
- A parallel and scalable iterative solver for sequences of dense eigenproblems arising in FLAPW - M. Berljafa, E. Angelo D. Napoli
- Sequential Monte Carlo in Bayesian assessment of contaminant source localization based on the sensors concentration measurements - A. Wawrzynczak-Szaban, P. Kopka, M. Borysiewicz
- Effective parallelization of quantum simulations: nanomagnetic molecular rings - P. Kozłowski, G. Musiał, M. Antkowiak, D. Gatteschi
- DFT study of the Cr8 molecular magnet within chain-model approximations - V. Bellini, D. M. Tomecka, B. Brzostowski, M. Wojciechowski, F. Troiani, F. Manghi, M. Affronte
|
|
18:40 - 20:00
|
Guided tour of Castle Square
The organizers provide buses from hotels: Campanile, Golden Tulip and Premiere Classe - departure at 18:40
|
|
20:00
|
Conference Dinner in "Sabat Theatre"
|
Wednesday, Sept. 11
Polish-Japanese Institute
|
|
8:40 – 10:00
|
Invited talks
Chairperson: Denis Trystram
- Communication Avoiding Algorithms: Recent Progress and Impact on Applications - Laura Grigori, INRIA
- Challenges and Solutions in Science Automation - Ewa Deelman, University of Southern California
|
|
10:00 – 10:20
|
Coffee break
|
|
10:20 – 12:00
|
Contributed papers (6 x 4 slots)
-
Track A: WS on Power and Energy Aspects of Computation
Chairperson: Rich Vuduc
- Invited talk:
Energy and Power Consumption Trends in HPC - Piotr Luszczek
- Measuring the sensitivity of graph metrics to missing data - A. Zakrzewska, D. A. Bader
- The energy/frequency convexity rule: modeling and experimental validation on mobile devices - K. De Vogeleer, G. Memmi, P. Jouvelot, F. Coelho
-
Track B: Main Track: Environments and Tools for Distributed/Cloud/Grid Computing
Chairperson: Andrzej Karbowski
- Efficient service delivery in complex heterogeneous and distributed environment - J. Kwiatkowski, M. Fras
- Domain-driven visual query formulation over RDF data sets - B. Balis, T. Grabiec, M. Bubak
- Towards high reliability of a multi-agent system designed for intrusion detection in MANET - L. Mechtri, F. Djemili T. Salim G.
- Secure storage and processing of confidential data on public clouds - J. Meizner, M. Bubak, M. Malawski, P. Nowakowski
-
Track C: WS on Language-Based Parallel Programming Models
Chairperson: Ami Marowka
- FooPar: a functional object oriented parallel framework in Scala - F. P. Hargreaves, D. Merkle
- Prototyping framework for parallel numerical computations - O. Meca, S. Böhm, M. Běhálek, M. Surkovsky
- Core allocation strategies on multicore platforms to accelerate forest fire spread predictions - T. Artés, A. Cencerrado, A. Cortés, T. Margalef
- Effects of segmented finite difference time domain on GPU - J. Mijares, P. Thulasiraman, R. Thulasiram, G. Battoo
-
Track D: MS on Communication Avoiding Algorithms for Linear Algebra
Chairperson: Laura Grigori
- Exploiting Data Sparsity in Parallel Matrix Powers Computations - N. Knight, E. Carson, J. Demmel
- Communication Avoiding ILU0 Preconditioner - L. Grigori, S. Moufawad
- Parallel Design and Performance of Nested Filtering Factorization Preconditioner - L. Grigori, F. Nataf, Long Qu
- Hiding global communication latency in the GMRES algorithm on massively parallel machines - W. Vanroose, P. Ghysels, K. Meerbergen, T. Ashby
-
Track E: MS on Applications of Parallel Computation in Industry and Engineering
Chairpersons: Raimondas Ciegis, and Julius Zilinskas
- Modeling and simulations of beam stabilization in edge-emitting broad area semiconductor devices - M. Radziunas, R. Ciegis
- Concurrent nomadic and bundle search: a class of parallel algorithms for local optimization - C. Voglis, D. Papageorgiou, I. Lagaris
- Parallel multi-objective memetic algorithm for competitive facility location - A. Lančinskas, J. Žilinskas
- Parallelization of encryption algorithm based on chaos system and neural networks - D. Burak
-
Track F: Main Track: Parallel Non-Numerical Algorithms
Chairperson: Pascal Bouvry
- Co-operation schemes for the parallel memetic algorithm - J. Nalepa, M. Blocho, Z. J. Czech
- Optimal diffusion for load balancing in heterogeneous networks - K. Dimitrakopoulou, N. Missirlis
- Parallel bounded model checking of security protocols - O. Siedlecka-Lamch, M. Kurkowski, S. Szymoniak, H. Piech
- Efficient parallel selection - C. Siebert
|
|
12:00 – 13:20
|
Invited talks
Chairperson: Peter Arbenz
- Are we expecting too much from GPUs? - Denis Trystram, Grenoble Institute of Technology
- How much (execution) time, energy, and power will my algorithm cost? - Richard Vuduc, Georgia Institute of Technology
|
|
13:20 – 13:30
|
Closing remarks
|
|
13:30
|
Lunch
|





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
 hide details
hide details